std::unique – linearly removes consecutive duplicates in a range (does not mean range must be sorted). Some time ago I had an issue it was too slow. And recently I had an idea how to solve it.
100% of the time I have encountered usage of std::unique – or similar implementation in different namespace – the input range was sorted.
This opens the possibility to replace linear search in favor of binary search. And so I did, I have replaced linear search with binary search.
template <typename TIterator>
TIterator faster_unique( TIterator begin, TIterator end )
{
TIterator value = begin;
TIterator next = value;
while ( next != end ) {
std::advance( next, 1 );
TIterator found = std::upper_bound( next, end, *value );
std::advance( value, 1 );
if ( found == end ) return value;
std::swap( *value, *found );
next = found;
}
return next;
}The result is as follows:
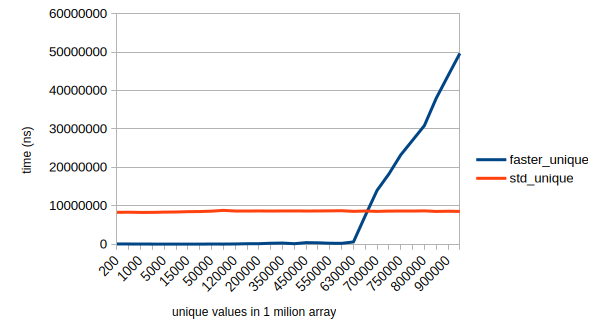
Conclusion: if you expect to have about 33% or more duplicates in a range, the faster_unique will be faster than standard implementation.
Caveat: this is a different algorithm than std::unique and it is not a direct replacement. it requires the input range to be sorted to work properly, while std::unique does not.
Testing and benchmarking has been done under Linux, with gcc 14.2.1, google benchmark 1.9.2
Github repo with the code + testing + benchmark is available under the following link:
https://github.com/xmaciek/faster_unique